2023. 7. 8. 23:59ㆍ혼공학습단 10기
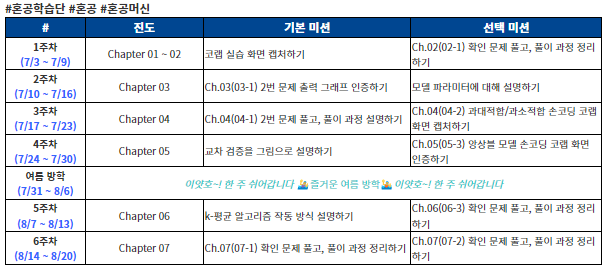
02-1 훈련 세트와 테스트 세트
지도 학습과 비지도 학습
지도 학습(supervised learning)
- 알고리즘이 정답을 맞히는 것을 학습
- 훈련 데이터(training data) = 입력(input) + 정답(target)
- 입력(input) : 데이터, ex) 길이와 무게 ( feature)
- 타깃(target) : 정답, ex) 도미, 빙어
비지도 학습(unsupervised learning)
- 입력데이터만 사용 = 타깃이 없다.
- 정답을 사용하지 않으므로 정답을 맞출 수 없다.
- 데이터를 파악하거나 변형하는데 사용
훈련 세트와 데스트 세트
- 훈련에 사용하는 훈련데이터와 테스트에 사용하는 테스트 데이터가 달라야 한다.
- 훈련에 사용한 데이터를 테스트에 사용하면 정답을 알고 시험을 보는 것과 마찬가지
- train set : 훈련에 사용하는 데이터
- test set : 테스트에 사용하는 데이터
코랩실습
데이터 준비하기
- 샘플(sample) : 하나의 데이터, ex) 하나의 생선 데이터

KNeighborsClassifier 객체 생성

train set, test set 분리

train set으로 모델 훈련, test set으로 모델 평가

샘플링 편향
- 훈련 세트와 데스트 세트에 샘플이 골고루 섞여 있지 않아 샘플링이 한쪽으로 치우쳐져 있는 상태
코랩 실습
인덱스 램덤하게 섞기

train set, test set 분리하기


모델 훈련, 모델 평가

test set의 예측 결과와 실제 target 비교

02-2 데이터 전처리
코랩실습
데이터 준비하기
- np.column_stack(), np.concatenate()

train set, test set 분리하기
- train_test_split()

stratify = True : 클래스 비율에 맞게 데이터를 나눈다.

모델 훈련, 모델 평가
- 모델 훈련, 모델 평가

- 도미 데이터 결과 확인
-> 빙어로 예측
-> 산점도를 눈으로 확인했을때는 도미로 판단이 된다.

- 샘플과 가장 가까운 5개 샘플 표시


기준 맞추기
x축과 y축 범위 맞추기
-> 길이와 무게의 범위가 다르다 = 두 특성의 scale이 다르다

데이터 전처리 ( data preprocessing )
- 특성값을 일정한 기준으로 맞추는 작업
- 표준점수( standard score ) = z score로 전처리 데이터 준비하기

- 전처리 데이터 확인하기
-> 샘플도 train set과 동일한 기준으로 train set의 mean과 std를 이용해서 전처리 해줘야 한다.
- 전처리 데이터로 모델 훈련 및 평가
-> test도 train set의 mean과 std로 전처리 해줘야 한다.



선택 미션
확인문제
1. 머신러닝 알고리즘의 한 종류로서 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습 방법은 무엇인가요?
1) 지도 학습
2) 비지도 학습
3) 차원 축소
4) 강화 학습
정답 1)
풀이 비지도 학습은 샘플의 입력만 알고 있을 때 사용한 수 있는 학습 방법이다.
2. 훈련 세트와 테스트 세트가 잘못 만들어져 전체 데이터를 대표하지 못하는 현상을 무엇이라고 부르나요?
1) 샘플링 오류
2) 샘플링 실수
3) 샘플링 편차
4) 샘플링 편향
정답 4)
풀이 룬련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향(sampling bias)라고 부른다.
3. 사이킷런은 입력 데이터(배열)가 어떻게 구성되어 있을 것으로 기대하나요?
1) 행 : 특성, 열 : 샘플
2) 행 : 샘플, 열 : 특성
3) 행 : 특성, 열 : 타깃
4) 행 : 타깃, 열 : 특성
정답 2)
풀이 입력 데이터는 샘플들의 특성 값으로 구성되어 있으며, 특성을 열, 샘플은 열로 구성되어 있다.
'혼공학습단 10기' 카테고리의 다른 글
| [혼공학습단10기] 혼자 공부하는 머신러닝+딥러닝 4주차 Ch_5 트리알고리즘 (0) | 2023.07.29 |
|---|---|
| [혼공학습단10기] 혼자 공부하는 머신러닝 + 딥러닝 3주차 Ch_4 다양한 분류 알고리즘 (0) | 2023.07.22 |
| [혼공학습단 10기] 혼자 공부하는 머시러닝 + 딥러닝 2주차 Ch_3 회귀 알고리즘과 모델 규제 (0) | 2023.07.15 |
| [혼공학습단 10기] 혼자 공부하는 머신러닝 + 딥러닝 1주차 - Ch_1 나의 첫 머신러닝 (2) | 2023.07.07 |