2023. 7. 7. 21:23ㆍ혼공학습단 10기

01-1 인공지능과 머신러닝, 딥러닝
인공지능
- 사람처럼 학습하고 추론한 수 있는 지능을 가진 컴퓨터 시스템을 만드는 기술
- 인공지능 구분
강인공지능(String AI) = 인공일반지능(Artificial General Intelligence)
사람과 구분하기 어려운 지능을 가진 컴퓨터 시스템ex) 터미네이터의 스카이
약인공지능(Weak AI)
특정 분야에서 사람의 일을 도와주는 보조 역활ex) 음성 비서, 자율 주행 자동차, 음악 추천, 기계 변역
머신러닝
- 자동으로 데이터에서 규칙을 학습하는 알고리즘을 연구하는 분야
- 통계학에서 유래된 머신러닝 알고리즘이 많다.
- 사이킷런(scikit-learn)
- 파이썬 API를 사용하여 배우기 쉽고, 컴파일하지 않아도 되기 때문에 사용이 편리
- 모든 머신러닝 알고리즘이 포함되어 있지는 않다.
- 대신, 포함된 알고리즘들은 안정적이고, 성능이 검증되어 있다.
딥러닝
- 머신러닝 알고리즘의 일부
- 인공신경망(Artificial neural network)을 기반으로 하는 방법들을 통칭
- 딥러닝 라이브러리
- 텐서플로(TensorFlow) - Google
- 파이토치(PyTorch) - Facebook
01-2 코랩과 주피터 노트북
코랩(Colab)
- 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스
- 크라우드 기반의 주피터 노트북 개발 환경
- 컴퓨터 성능과 산관없이 프로그램 실습 가능
셀
- 셀(cell) : 코랩에서 실행할 수 있는 최소단위
노트북
- 주피터 노트북 : 주피터 프로젝트의 대표 제품
- 코랩은 구글이 대화식 프로그래밍 환경인 주피터(Jupyter)를 커스터마이징
코랩 노트북 실습
1) 'Hello World' 출력

2) 노트북 이름 변경

01-3 마켓과 머신러닝
생선 분류 문제
- 도미 데이터 준비하기

classification(분류) : 여러개의 종류(class) 중 하나를 구별하는 문제
binary classification(이진 분류) : 2개의 클래스 중 하나를 고르는 문제
feature(특성) : 데이터의 특징
ex)도미의 길이, 무게
- 산점도(scatter plot) 통해 도미의 특성(feature) 파악하기
- 도미의 길이와 무게는 linear(선형)적이다.

scatter plot(산점도) : x, y축으로 이뤄진 좌표계에 두 변수(x, y)의 관계를 표현하는 방법
matplotlib : 파이썬에서 과학계산용 그래프를 그리는 대표적인 패키지
- 빙어 데이터 준비하기

- 산점도(scatter plot) 통해 빙어의 특성(feature) 파악하기
- 빙어의 길이와 무게는 선형적
- 길이가 늘어난 정도에 비해 무게는 많이 늘지 않음
- 무게가 길이에 영향을 덜 받음

- 도미와 빙어 데이터 합치기

- 도미와 빙어를 숫자 1과 0으로 표현하기

- training
= fish_data와 fish_target으로 도미를 찾기 위한 기준을 학습시키기
- fit() : 사이킷런에서 training하는 메서드

- 평가하기
- 정확도를 계산
- 정확도 = (정확히 맞힌 개수) / (전체 데이터 개수)

k-Nearest Neighbors(k-최근접 이웃) 알고리즘
k-최근접 이웃 알고리즘
- 주위의 다른 데이터를 보고 다수를 차지하는 것을 정답으로 사용
- 단점
- 데이터가 아주 많은 경우 사용하기 어렵다.
- 메모리가 많이 필요, 계산하는 데 시간이 많이 소요
- n_neighbors = 5 ( default value)

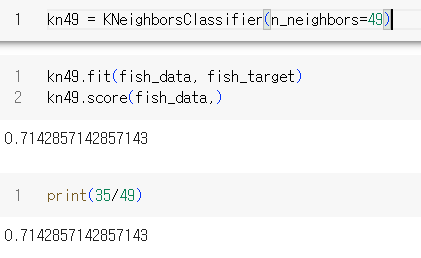
n_neighbors=49인 k-Nearest Neighbors
- 가장 가까운 데이터 49개를 사용
- 전체 데이터 49개, 도미 데이터 35개
- 도미 데이터가 다수를 차지하므로 무조건 도미로 예측
- fish_data를 평가하면 도미만 맞추게 된다.
'혼공학습단 10기' 카테고리의 다른 글
| [혼공학습단10기] 혼자 공부하는 머신러닝+딥러닝 4주차 Ch_5 트리알고리즘 (0) | 2023.07.29 |
|---|---|
| [혼공학습단10기] 혼자 공부하는 머신러닝 + 딥러닝 3주차 Ch_4 다양한 분류 알고리즘 (0) | 2023.07.22 |
| [혼공학습단 10기] 혼자 공부하는 머시러닝 + 딥러닝 2주차 Ch_3 회귀 알고리즘과 모델 규제 (0) | 2023.07.15 |
| [혼공학습단 10기] 혼자 공부하는 머신러닝 + 딥러닝 1주차 Ch_2 데이터 다루기 (0) | 2023.07.08 |